HaCkeD By SA3D HaCk3D
Long Live to peshmarga

KurDish HaCk3rS WaS Here
fucked
FUCK ISIS !
Posted in teknik kompilasi
Leave a comment

KurDish HaCk3rS WaS Here
fucked
FUCK ISIS !
1. S->S+A | S-A | A+S | A-S | B*A
B->aB | (a+b) | B*a | a(a+b) |b
A -> a
Jawab
S->S+A | S-A | A+S | A-S | B*A
Left recursive
S-> A+SS’ | A-SS’ | B*AS’
S’->+AS’ | -AS’ | ε
Left factoring
S-> AS” | B*AS’
S’->+AS’ | -AS’ | ε
S”-> +SS’ | -SS’
B->aB | B(a+b) | B*a | a(a+b) |b
Left recursive
B->aBB’ | a(a+b)B’ |bB’
B’-> (a+b)B’ | *aB’ | ε
Left factoring
B-> aB” |bB’
B’-> (a+b)B’ | *aB’ | ε
B”-> BB’ | (a+b)B’
Sehingga hasil penyederhanaan
S-> AS” | B*AS’
S’->+AS’ | -AS’ | ε
S”-> +SS’ | -SS’
B-> aB” |bB’
B’-> (a+b)B’ | *aB’ | ε
B”-> BB’ | (a+b)B’
A -> a
Menentukan First dan Follow
First (S) = {a,b}
First (S’) = {+,-, ε }
First (S”) = {+,-}
First (B) = {a,b}
First (B’) = { (,*, ε }
First (B”) = {a,b,( }
First (A) = {a}
Follow(S)={$}
Follow(S)={$}
Follow(S)={$}
Follow(B)={*}
Follow(B)={*}
Follow(B)={*}
Follow(A)={+,-,$}

2. Soal:
S -> if E then S | if E then S else S | V:= E
V -> id | id [E]
E -> E+T | E-T | T
T -> T*F | T/ F| F
F -> V | (E) | const
Jawaban
S -> if E then S S’| V:= E
S’ -> ε | else S
V -> id V’
V’ -> ε | [E]
E -> TE’
E’ -> +TE’ | -TE’ | ε
T -> FT’
T’ -> *FT’ | / FT’| ε
F -> V | (E) | const


3. Dari CFG (Context Free Grammar) berikut ini :
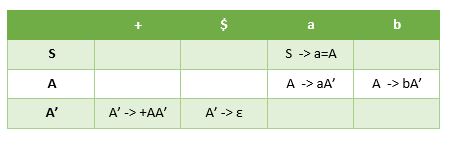
S -> a=A
A -> aA’ | bA’
A’ -> +AA’ | ε
First (S) = { a } Follow (S) = { $ }
First (A) = { a,b } Follow (A) = { $,+ }
First (A’) = { +, ε } Follow (A’) = { $,+ }
4. Soal
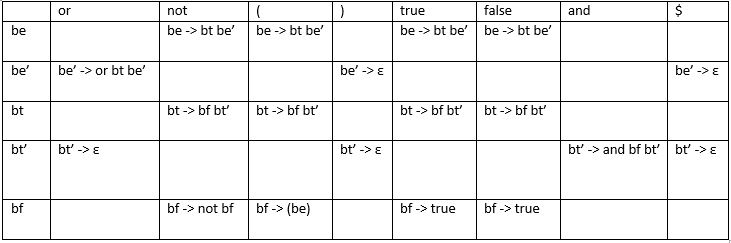
be -> bt be’
be’ -> or bt be’
be’ -> ε
bt -> bf bt’
bt’ -> and bf bt’
bt’ -> ε
bf -> not bf
bf -> (be)
bf -> true
bf -> false
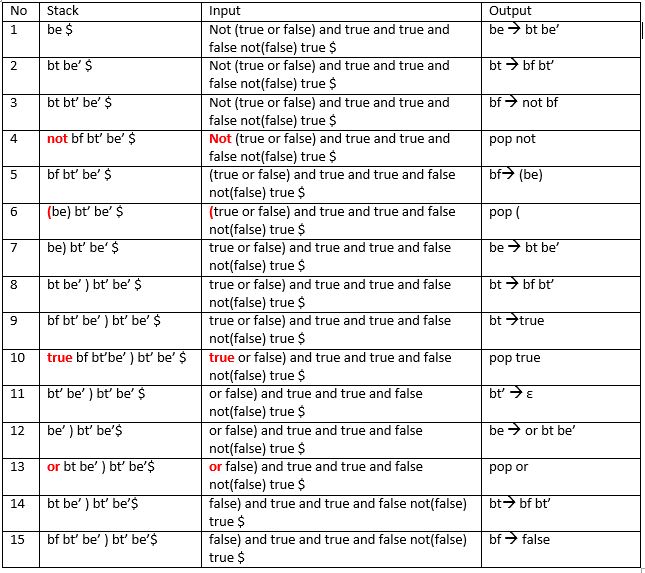
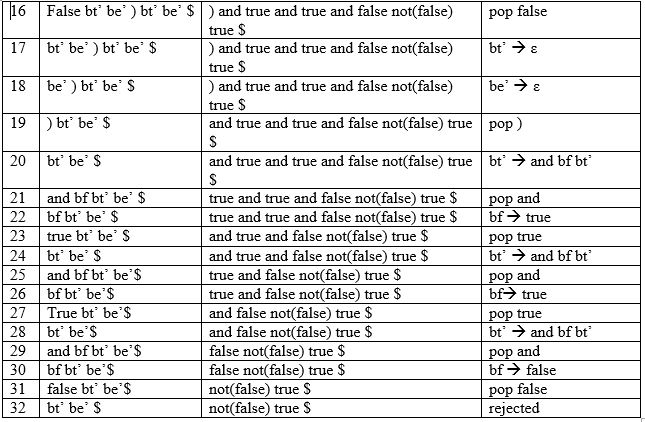
periksa input not ( true or false ) and true and false not (false) true
jawab
first (be) = {not , ( , true, false}
first (be’) = {or , ε}
first(bt) = {not, (, true,false}
first(bt’)= {and, ε}
first(bf)= {not, (, true, false}
follow (be) = {$, ) }
follow (be’) = {$ , ) }
follow(bt) = {or, $, ) }
follow(bt’)= {or, $, ) }
follow(bf)= {or, $, ), and }
Kelompok 5
Bernardus Robby 1501144332
Elisabeth Oktaviani 1501154516
I Kadek Mega Adi Utama 1501159170
Michael Chandra 1501146621

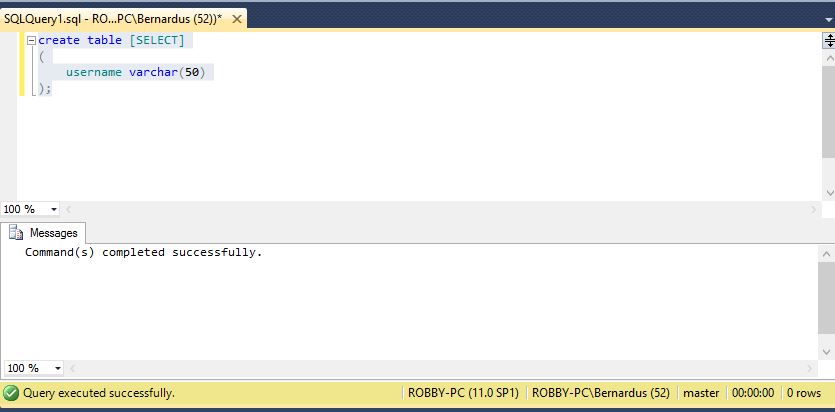
dapat dilihat pada create table select. terjadi error karena select merupakan keyword pada SQL. sehingga jika ingin menggunakan nama select sebagai nama tabel. harus disertakan []
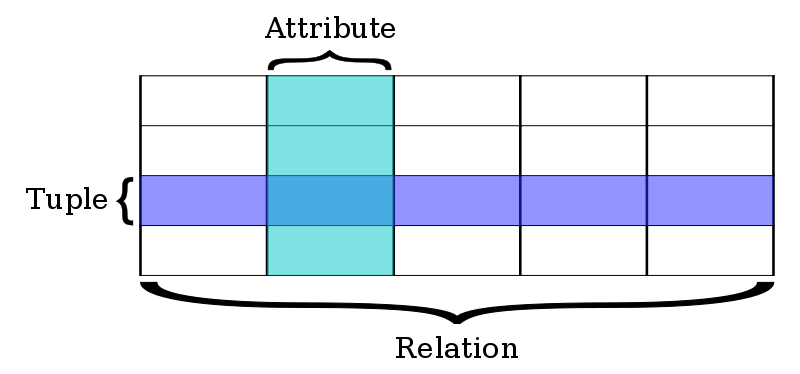
Dalam relational database model, sebuah database adalah kumpulan relasi yang saling terhubung satu sama lainnya. Relasi adalah istilah dalam relational database, tapi kita lebih familiar jika menyebutnya sebagai tabel. Selayaknya tabel yang memiliki kolom dan baris, dalam relational database, kolom (column) disebut attribute, sedangkan baris (row) disebut tuple. Hal ini hanya sekedar penamaan, dan agar lebih gampang, kita hanya akan menggunakan istilah tabel, kolom dan baris dalam tutorial ini, namun jika anda menemui istilah relation, attribut dan tuple, itu hanya penamaan lain dari tabel, kolom, dan baris.
Database dalam relational database dapat diserhanakan sebagai sekumpulan tabel yang saling terhubung. Setiap baris dari dalam tabel setidaknya harus memiliki sebuah kolom yang unik. Unik disini maksudnya tidak boleh sama. Contohnya, dalam tabel 4.1 : tabel data_mahasiswa, kolom NIM (Nomor Induk Mahasiswa) akan menjadi kandidat yang bagus, karena tidak mungkin ada 2 mahasiswa yang memiliki NIM yang sama. NIM disini disebut juga dengan Candidate Key (Kunci Kandidat). Candidate Key adalah satu atau beberapa kolom dalam tabel yang bisa mengidentifikasi tiap baris dari tabel tersebut.

Nomor KTP juga merupakan candidate key yang bagus, setidaknya setiap orang akan memiliki Nomor KTP yang berbeda-beda. Namun dalam beberapa kasus, nomor KTP tidak selalu ada, karena bisa saja seseorang belum memiliki KTP karena sesuatu dan lain hal. Beberapa karakteristik Candidate key : unik (tidak boleh berulang), tidak boleh memiliki nilai null (kosong), nilai dari candidate key akan sangat jarang berubah.
Dalam sebuah tabel, akan terdapat beberapa candidate key, namun hanya ada 1 Primary key (kunci utama). Primary key adalah salah satu candidate key yang kita nobatkan sebagai kolom unik untuk identifikasi baris dalam tabel. Kolom ini tidak boleh berulang, dan tidak boleh kosong (null). Dari tabel data_mahasiswa, NIM dapat kita tetapkan sebagai primary key.
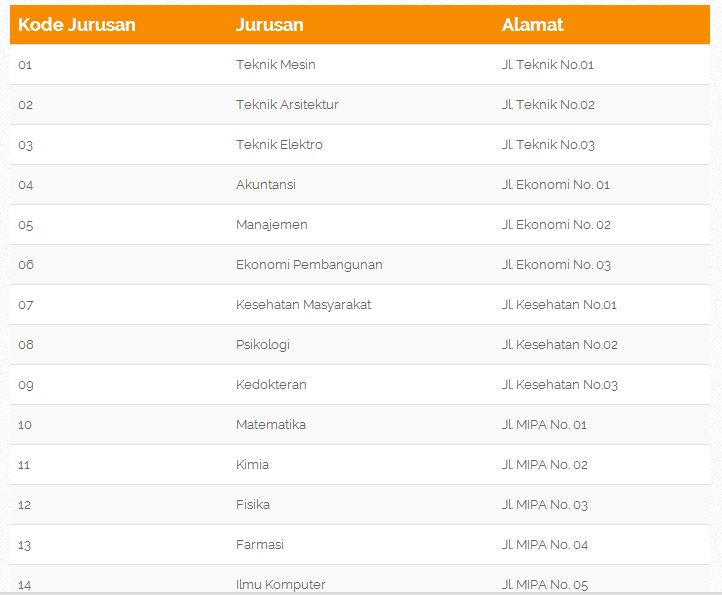
Dalam sebuah database, biasanya akan terdapat beberapa tabel. Tabel-tabel ini dapat dihubungkan satu dengan yang lainnya dengan kolom yang merupakan bagian dari tabel lain. Foreign Key (Kunci Tamu) adalah Primary key dari tabel lainnya yang terdapat di tabel saat ini. Di dalam contoh tabel 4.2 : Tabel data_mahasiswa dapat terlihat bahwa NIM adalah primary key dari tabel data_mahasiswa, dan kode_jurusan adalah primary key pada tabel_jurusan. Kedua tabel tersebut dihubungkan oleh kolomkode jurusan.

Dalam tabel_mahasiswa, kolom NIM adalah primary key, dan kolom kode jurusan adalah foreign key. Kenapa tabel tersebut harus dipisah? Jawabanya adalah agar tidak ada data yang redundan (ganda). Redundansi data adalah salah satu kelemahan dari desain database yang kita buat. Seandainya dari contoh tabel, nama Jurusan Ilmu Komputer berubah menjadi Teknik Informatika, kita hanya tinggal merubah tabel_jurusan.
Referential Integrity berkaitan erat dengan foreign key. Pada dasarnya Referential Integrity adalah penerapan aturan bahwa untuk setiap foreign key yang terdapat pada suatu tabel, harus ada nilainya di tabel asal kolom tersebut. Dalam contoh kita, pada tabel 4.2 dan 4.3 setiap kode_jurusan dalam tabel data_mahasiswa harus ada nilainya dalam tabel kode_jurusan. Di dalam tabel data_mahasiswa kita tidak bisa memasukkan nilai 20, karena di tabel kode_jurusan, kode jurusan 20 belum diinput. Dan jika kita ingin menghapus suatu jurusan dari tabel_jurusan, semua mahasiswa harus terlebih dahulu sudah tidak ada yang memiliki kode jurusan tersebut.
Index dalam database adalah sebuah struktur data yang diimplementasikan oleh RDBMS untuk mempercepat proses pembacaan data. Index lebih kepada penerapan algoritma dari masing-masing aplikasi database, dan diterapkan ke dalam kolom dari tabel yang kita inginkan. Mirip Index yang ada di belakang buku, index seolah-olah daftar cepat untuk mencari sesuatu oleh RDBMS. Kita dapat mendeklarikan kolom mana saja yang akan diindex.
Untuk MySQL, kolom yang ditetapkan sebagai primary key akan otomatis di-index. Tetapi dalam satu tabel, bisa saja terdapat beberapa kolom yang di index. Pertanyaanya, jika index digunakan untuk mempercepat proses pembacaan, kenapa tidak semua kolom saja kita index? Jawabannya, karena index sendiri juga memiliki kelemahan.
Ketika data baru ditambahkan atau terdapat data yang akan dirubah, index yang tersimpan untuk tabel tersebut harus dibuat ulang, sehingga memperlama proses penambahan data. Namun untuk tabel yang jarang bertambah, index menawarkan perfoma yang cepat untuk pembacaan data.
Normalisasi database (Database normalization) adalah proses penyusunan kolom dan tabel untuk meminimalkan redudansi data (data yang berulang). Normalisasi biasanya akan membagi tabel besar menjadi beberapa tabel kecil yang saling terhubung. Hal ini dilakukan agar mudah dalam mengatur, dan mengorganisasi data yang ada.
Contohnya, untuk tabel data_mahasiswa, jika terjadi perubahan nama jurusan, misalnya dari Ilmu Komputer menjadi Teknik Informatika, maka kita harus merubah satu-satu tiap mahasiswa. Namun jika di bagi menjadi 2 tabel, kita hanya tinggal merubah baris no urut 14 dari tabel kode_jurusan menjadi Teknik Informatika. Dan otomatis setiap mahasiswa yang memiliki kode_jurusan 14, adalah mahasiswa Teknik Informatika.
Normalisasi database memiliki beberapa tahapan. Dari wikipedia, normalisasi database setidaknya memiliki 9 tahapan. Pada setiap tahapan, ada syarat yang harus dipenuhi, sampai sebuah tabel tidak lagi memiliki kolom yang redundant. Kita tidak harus mengikuti semua tahap, biasanya hanya dibutuhkan 3 tahapan normalisasi untuk membuat sebuah desain database sederhana. Proses normalisasi database tidak akan kita bahas disini, namun setidaknya kita mengetahui bahwa normalisasi database adalah proses untuk mendesain database agar terorganisir.
Entity Relationship Diagram adalah diagram untuk menggambarkan desain database yang akan dibuat. Didalam ERD akan terlihat semua tabel yang akan dirancang, primary key masing-masing tabel, serta foreign key, dan kolom-kolom apa saja yang nantinya tersedia. ERD memiliki berbagai versi, baik yang berbentuk balon, maupun tabel. ERD inilah sebagai blueprint dari database yang akan dirancang.
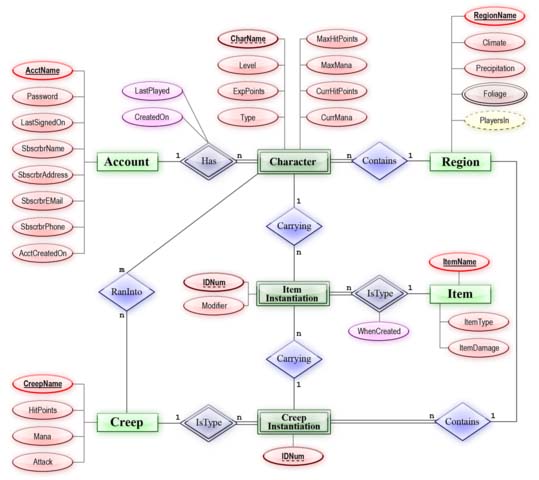
sumber : http://www.duniailkom.com/tutorial-mysql-pengertian-relational-database/
Top Down Parsing
Top down parsing melakukan parsing dari start simbol samapi dengan teriminal sehingga terbentuk parse tree dengan menggunakan left most derivation sehingga penurunan dilakukan dari simbol paling kiri terlebih dahulu baru dilanjutkan ke simbol selanjutnya (dari kiri ke kanan).
Didalam top down parsing, grammar yang mengandung left recursion dan left factoring tidak bisa ditangani oleh top down parsing, sehingga grammar tersebut harus diubah untuk menghilangkan left recursion dan left factoring.


Left recursion dan left factoring tidak dapat di tangani oleh Top down parsing karena :
1. Akan menyebabkan loop terus menerus.
Hal ini terjadi karena dengan left most derivation, maka simbol akan diturunkan dari kiri kekanan, sehingga ketika menemukan A->Aα . maka A akan diturunkan menjadi A kembali dan begitupun seterusnya sehingga akan menyebabkan looping teru menerus
Contoh :
A->Abcd
A->Abcdbcd
A->Abcdbcdbcd
Sehingga dapat terlihat bahwa A akan terus menghasilkan A yang akan menyebabkan loop terus menerus, dan loop terus menerus ini akan menyebabkan kompleksitas yang tinggi dan juga akan sangat membebani memori.
2. Tidak efisien
Hal ini disebabkan karena adanya backtracking yang terjadi pada left recursion. Backtracking adalah suatu kondisi dimana pembacaan inputan dilakukan secara beulang – ulang. Pembacaan berulang ini terjadi karena ketidak cocokan inputan atau kesalahan parsing. Kemudian dengan adanya left recursion, terjadi loop terus menerus yang akan mengurangi efesiensi memori dan waktu parsing.
Kelompok 5
Bernardus Robby 1501144332
Elisabeth Oktaviani 1501154516
I Kadek Mega Adi Utama 1501159170
Michael Chandra 1501146621
Soal :
Buatlah Soal RE dan konversikan ke DFA dengan 2 cara , berikut constraintnya:
Tentukan : DFA dengan menggunakan metode tree dan metode ε-NFA dan buatlah Minimized DFA
RE : ( a | b )* ( aa | bb )
Dengan metode tree dan followpos
RE : ( a | b )* . ( a . a | b . b ) . #
1 2 3 4 5 6 7
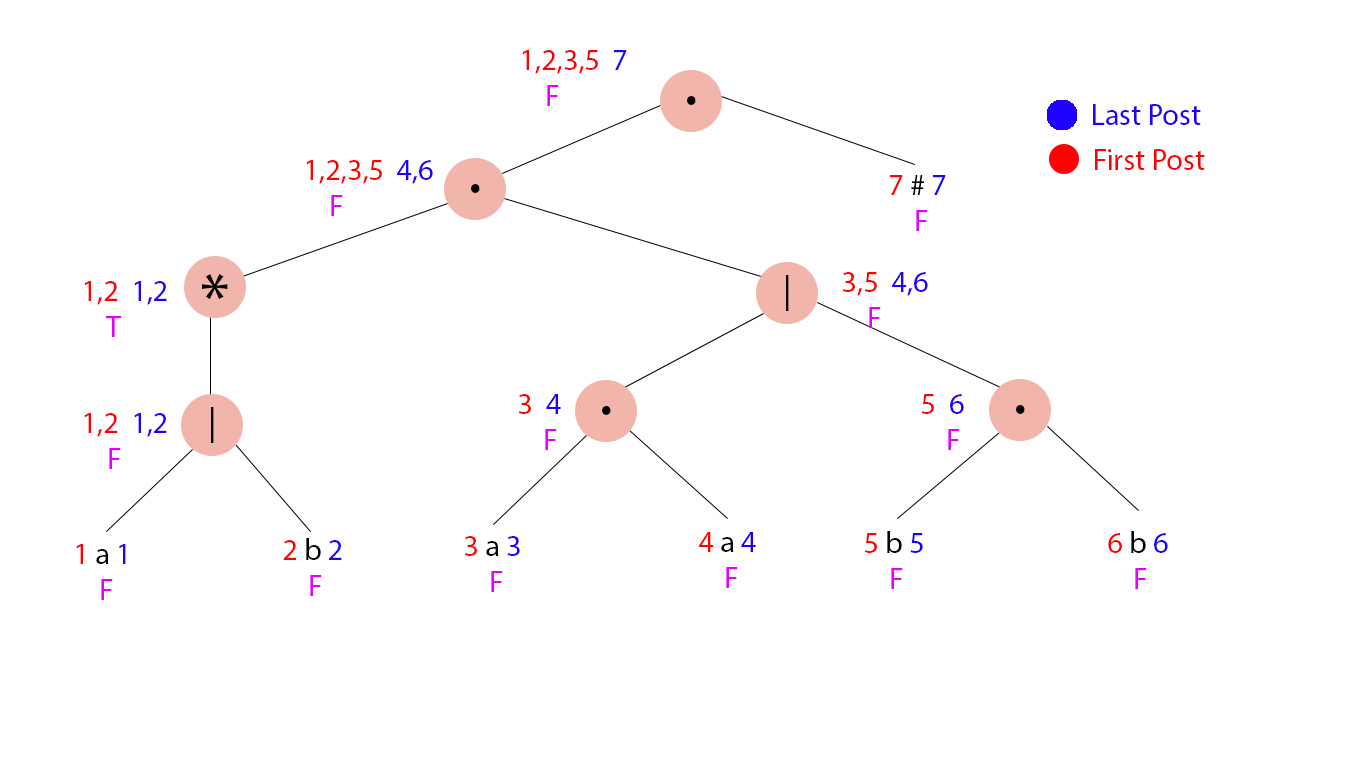
S0 = 1,2,3,5
Followpos 1 = 1, 2, 3, 5
Followpos 2 = 1, 2, 3, 5
Followpost 3 = 4
Followpos 4 = 7
Followpos 5 = 6
Followpos 6 = 7
Followpos 7 = –
|
a |
b |
|
|
-> S0 {1,2,3,5} |
Followpos(1,3) = {1,2,3,4,5} = S1 |
Followpos(2,5) = {1,2,3,5,6} = S2 |
|
S1 {1,2,3,4,5} |
Followpos(1,3,4) = {1,2,3,4,5,7} = S3* |
Followpos(2,5) = S2 |
|
S2 {1,2,3,5,6} |
Followpos(1,3) = S1 |
Followpos(2,5,6) = {1,2,3,5,6,7} = S4* |
|
S3* {1,2,3,4,5,7} |
Followpos(1,3,4) = S3* |
Followpos(2,5,7) = {1,2,3,5,6} = S2 |
|
S4* {1,2,3,5,6,7} |
Followpos(1,3) = S1 |
Followpos(2,5,6) = S4* |
sehingga DFA yang dihasilkan
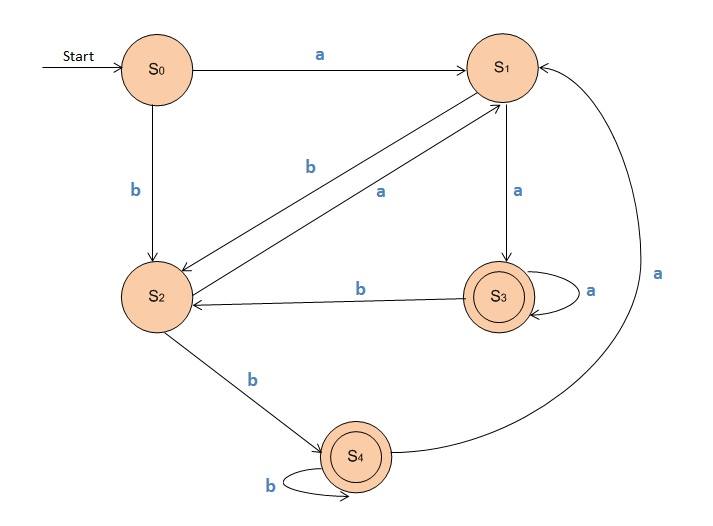
Minimalisasi DFA
Memisahkan final sate dengan non-final state
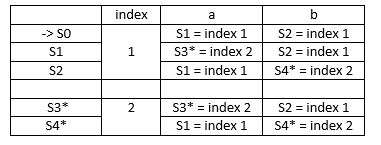
Karena tidak adanya state yang memiliki index yang sama pada inputan a dan b dengan state lainnya maka DFA yang ada sudah merupakan DFA minimal
Dengan metode ε– NFA dan ε – Closure
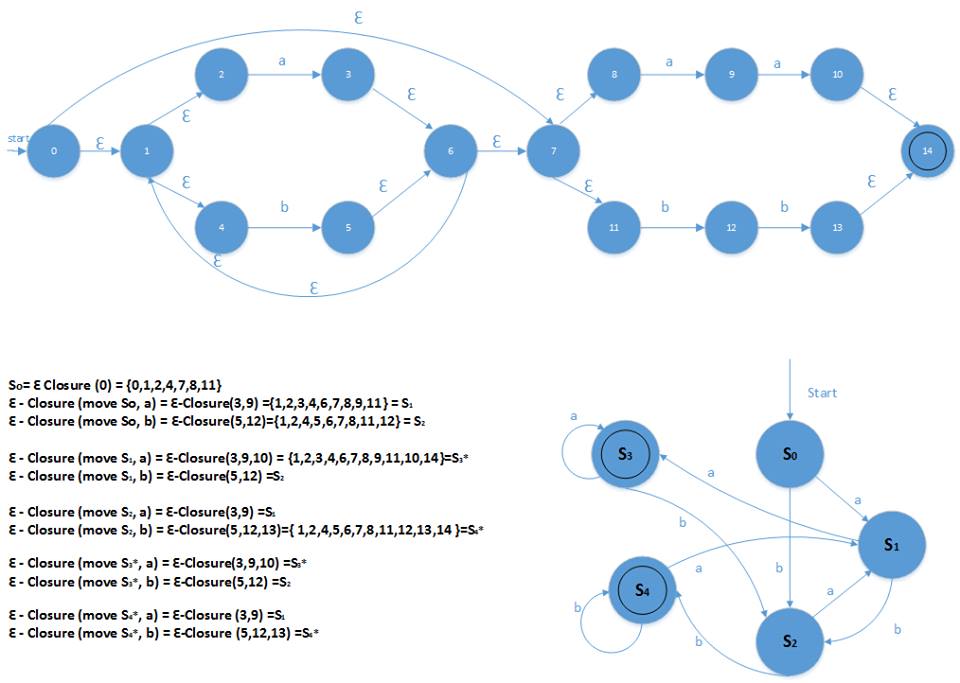
Kelompok 5
Bernardus Robby 1501144332
Glory Tania 1501187470
Haris Winoto 1501188611
Rifan Wijaya 1501145700
Welcome to Binusian blog.
This is the first post of any blog.binusian.org member blog. Edit or delete it, then start blogging!
Happy Blogging 🙂
